K8s 网络碎碎念
以下内容作为这段时间研究Kubernetes网络的总结,一口气写完,代表了当前对Kubernetes网络的认知,可能有误,权当摆龙门阵。
K8s网络的核心问题
我们理一理Kubernetes相关概念和网络的关系
- Pod:调度的基本单位,一个pod内的所有容器共享一个主机IP
- Deployment:管理Pod的资源
- StatefulSet:同样是管理Pod的资源,只不过是有状态的,其管理的主机IP创建后就不变了
- DaemonSet:也是管理Pod的资源
- Service:为Pod提供稳定的前端IP,同时能够通过QFDN的形式提供稳定的域名
- Ingress:允许以域名的形式访问Service
可以看到,Kubernetes的网络主要有以下几个方面
- 同一个集群内,Pod之间要能够相互通信
- Service提供负载均衡作用
- 需要有一个域名解析系统,为Service提供域名
- Ingress提供应用层网关作用
还有一个方面没有提到,但也很重要
- 网络策略:限制网络资源之间网络访问的规则
总计五个方面。
K8s网络的底层原理
- Pod之间相互通信
- Pod只是逻辑抽象,最终管理的还是容器,只不过Pod的实现,是先启动一个简单的pause容器,占据一个网络命名空间,其它容器创建时加入这个命名空间就行了
- 对于多节点集群,还涉及到IP划分的问题,一个简单的方案是:在集群的CIDR为每个主机划分一个子网,Pod从所属主机的IP池申请一个IP即可。flannel就是这样的实现
- 同节点上的Pod,只需要通过veth pair + linux bridge的方式即可实现通信
- 跨节点的Pod,则需要进行协调,一般的实现方式有
- 隧道协议:即网络插件直接将原IP包再包一层,在Node之间进行转发,到达目标节点后再拆包然后路由到目标Pod。隧道一般有一个发送前装包,发送后拆包的步骤,这一般通过tun设备实现。
- 直接路由:直接配置路由表,纯转发,没有封包的动作,性能好。但这要求所有节点都必须在同一个物理网络下。如果跨物理网络了,则需要BGP边界网关协议
- Service负载均衡
- 这个一般有两种实现方式:iptables和IPVS。都是配置一系列规则,但iptables本身是为防火墙而生,有规则麻烦效率低的缺点,在超大规模集群中这就是问题,IPVS是实现在内核层的负载均衡,专门用来负载均衡,效率高,但也有功能单一的缺点,注入NAT之类的功能还是需要iptables辅助
- Ingress应用层网关
- 这就是一个纯应用层的东西,直接将Nginx改造成Nginx-Ingress-Controller就能实现。正是由于其所处的位置,与应用有很大关系,切入点比较好,因此产生了一大堆Ingress-Controller:Kong、ApiSix、Traefik。。。
- 服务发现
- 即如何发现集群内的其它服务,有两种实现方式
- 环境变量:将集群内的所有服务IP通过环境变量的形式注入
- 域名解析系统:用域名的方式解析得到服务的IP
- 即如何发现集群内的其它服务,有两种实现方式
- 网络策略
- 简单的实现也可以通过iptables实现
- 但是更高效的可以通过eBPF实现,它能在没有多少性能损失的情况下实现对网络包的任意处理,低至4层,高至7层,可以说强大无比。Cilium就是在他的基础上开发的。
总结一下用到的底层技术
- Linux Network Namespace
- Veth pair
- Linux Bridge
- tun设备
- 隧道协议:IPIP、VXLAN等
- iptables
- IPVS
- eBPF
- DNS
K8s的网络组件
Kube-proxy
Kubelet
API Server
ETCD
Scheduler
RC
CoreDNS
与网络相关的有
Kube-proxy:其主要职责就是负责Service的实现,它定期拉取集群的网络配置,更新自己的规则。有三种工作模式
- userspace:这种情况下,Kube-poxy自己就是负载均衡器
- iptables:将配置的访问规则转换为本机的iptables规则,这种情况下负载均衡由iptables实现
- IPVS:效率更高
CoreDNS:负责域名解析系统
CNI插件:CNI接口基本来说就两个
- 为容器添加Network
- 为容器删除Network
所以他就是集群的IP管理系统,同时网络分配后,它还需要确保网络的可达性,毕竟网络分配方式是你规定的,自然也只有你知道如何才能访问到对应的网络。你看,都保证可达性了,网络策略就是在限制各种可达性,这不又得支持一下,所以总结起来就是
- 为Pod分配IP地址
- 保证Pod之间的连通性
- 提供Pod之间的网络访问策略
Kube-proxy和CNI的关系?
Kube-poxy应该说是建立在CNI之上的,它不管Service背后的网络是否能够被访问到,只管将数据包转发过去就行了。保证这个数据包能够正确到达目的地是CNI插件的事情。
K8s网络的解决方案
通常所说的K8s网络解决方案,指的就是各种CNI插件。这是CNI插件的主页:https://github.com/containernetworking/cni。可以看到不只是Kubernetes采用了CNI,Open Shift、Mesos等都采用了CNI。
- Flannel:功能简单,因此配置简单,使用方便。但是也有性能一般、IP浪费等情况出现。这是元老级别的CNI插件
- Callico:工作在三层,即IP层,纯路由方式实现,因此速度应该比较快。纯三层的有点就是可以直接路由,没有NAT、封拆包等性能损耗的东西。但是规模稍大的集群,则需要通过BGP连接同集群下的两个数据中心
- Cilium:基础功能和Flannel差不多,但采用了eBPF,功能和性能都应该会非常强大。最为典型的一点是,它能够在内核中对7层数据做处理,这个就很强了。
- Weave:一个多主机网络,去中心化。没搞懂它特殊在哪里🤔
一般Flannel和Callico会被放在一起比较
K8s和Service Mesh之间的关系
我们可以看到,K8s的网络包括CNI插件解决的是最最基本的问题:可达性。但是在实际开发中,还有大量的应用层面的共性任务需要处理
- 日志采集
- 链路追踪
- 服务熔断和降级
- 灰度发布
- 。。。
Service Mesh就是为了解决这些问题出现的,云计算的发展趋势就是这样,逐步将底层共性的技术抽象出来,通过底座的形式提供,这种发展的终极形式看起来就是Serverless。当然,Serverless有冷启动、可靠性等固有缺点,因此只能用来提供弱业务的功能。强业务方面,短时间看就是K8s了。Service Mesh就是这一脉络的发展方向。
至于说Service Mesh和网络有什么关系呢?
我们知道,传统K8s的网络架构如下
- CNI为网络基座,提供基本可用性
- Service提供访问固定入口和负载均衡
- Pod作为最小的网络单元
Service Mesh在每个Pod中注入一个sidecar,相当于把Service融入到了每个Pod,这样管理起来更加灵活。与此同时,K8s的Service就可以不要了
- Kube-proxy拦截的是进入节点的流量
- sidecar拦截的是进入Pod的流量
是不是有点晕
网络的特殊性,使得能够拦截网络流量的组件能够做很多事,比如CNI看起来只是分配了网络,但还负责网络的可达性和访问策略,甚至有的CNI插件也会实现Service功能;Istio在每个pod注入的side car将Kubernetes Service替换掉了。看起来一个网络库能够实现所有K8s网络相关服务,但其实不是的,总体还是CNI插件提供基础网络能力;上层库如Envoy提供应用层能力。
说到将Service融入每个Pod,Cilium也做了类似的事,不过更进一步,它是在内核层面做这件事,Istio是通过用户态程序Envoy实现,相比之下效率慢了不少。那Envoy和Cilium的关系是什么呢?
还是一个应用层、一个网络基础层,它们之间的关系大概如下
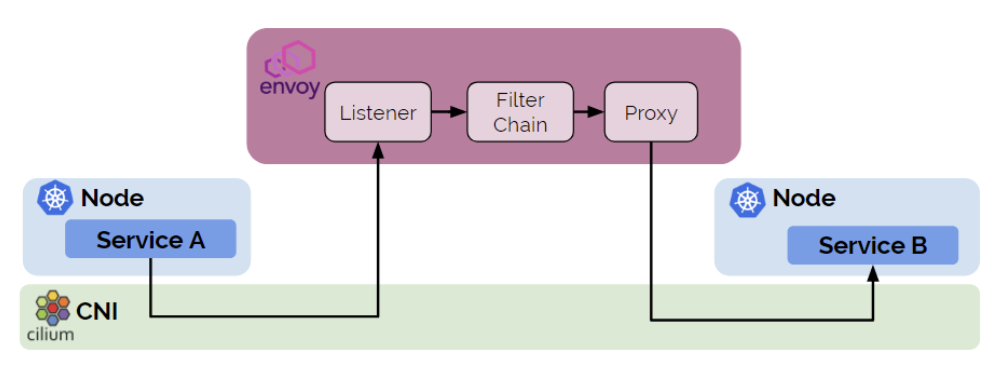
有了Istio,还需要CNI插件吗?
当然还是需要的,尽管Istio自己也有提供CNI插件,但那也是CNI插件呀。